반응형
Seaborn 에는 여러가지 그래프가 있는데요, Seaborn에서 제공하는 예제 데이터셋 로드하여 주요 그래프 기능을 알아보겠습니다.
데이터 준비
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Seaborn에서 제공하는 예제 데이터셋 로드
tips = sns.load_dataset('tips')
iris = sns.load_dataset('iris')
flights = sns.load_dataset('flights')
# 그래프 스타일 설정
sns.set(style="whitegrid")
1. Tips 데이터셋
tips 데이터셋은 레스토랑에서 받은 팁에 관한 정보를 포함하고 있습니다. 이 데이터셋은 고객의 성별, 흡연 여부, 식사 시간, 요일, 테이블 인원 수, 총 청구 금액, 팁 금액 등의 변수를 포함합니다. 이 데이터는 주로 범주형 변수와 연속형 변수를 다루는 예제를 위해 사용됩니다.
주요 컬럼
- total_bill: 총 청구 금액
- tip: 팁 금액
- sex: 성별 (Male/Female)
- smoker: 흡연 여부 (Yes/No)
- day: 요일 (Thur, Fri, Sat, Sun)
- time: 식사 시간 (Lunch/Dinner)
- size: 테이블 인원 수
2. Iris 데이터셋
iris 데이터셋은 머신러닝에서 가장 유명한 데이터셋 중 하나로, 붓꽃(Iris) 꽃의 품종을 예측하는 문제에 사용됩니다. 각 샘플은 네 개의 특성을 가지며, 각각의 특성은 꽃잎과 꽃받침의 길이와 너비입니다. 세 개의 붓꽃 품종 중 하나로 라벨링 되어 있습니다.
주요 컬럼
- sepal_length: 꽃받침의 길이 (cm)
- sepal_width: 꽃받침의 너비 (cm)
- petal_length: 꽃잎의 길이 (cm)
- petal_width: 꽃잎의 너비 (cm)
- species: 붓꽃의 품종 (setosa, versicolor, virginica)
3. Flights 데이터셋
flights 데이터셋은 1949년부터 1960년까지 매월 항공 승객 수를 기록한 데이터셋입니다. 이 데이터셋은 시계열 데이터를 다루는 예제에 자주 사용됩니다.
주요 컬럼
- year: 연도
- month: 월 (Jan, Feb, ..., Dec)
- passengers: 해당 월의 항공 승객 수
1. Scatterplot (산점도)
두 변수 간의 관계를 시각화합니다. 여기서는 tips 데이터셋을 사용합니다.
- 각 점은 하나의 데이터 포인트를 나타내며, x축과 y축은 변수의 값을 나타냅니다.
- 사용법: sns.scatterplot(x='column_x', y='column_y', data=dataframe)
예제 코드
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x='total_bill', y='tip', data=tips)
plt.show()
2. Barplot (막대 그래프)
범주형 데이터의 평균 또는 합계를 시각화합니다. 여기서는 tips 데이터셋을 사용합니다.
- 사용법: sns.barplot(x='category', y='value', data=dataframe)
plt.figure(figsize=(10, 6))
sns.barplot(x='day', y='total_bill', data=tips)
plt.title('Barplot of Total Bill by Day')
plt.show()
3. Lineplot (선 그래프)
시간의 흐름에 따른 데이터 변화를 시각화합니다. 여기서는 flights 데이터셋을 사용합니다.
- 사용법: sns.lineplot(x='time', y='value', data=dataframe)
sns.lineplot(x='time', y='total_bill', data=tips)
plt.show()4. Histogram (히스토그램)
- 설명: 데이터의 분포를 시각화하는 데 사용됩니다. 연속형 변수의 분포를 막대 그래프로 나타냅니다.
- 사용법: sns.histplot(dataframe['column'], bins=number_of_bins)
sns.histplot(tips['total_bill'], bins=20)
plt.show()5. Boxplot (상자 그림)
- 설명: 데이터의 분포와 변동성을 요약하여 시각화하는 데 사용됩니다. 중앙값, 사분위수, 최댓값, 최솟값을 포함한 통계 정보를 제공합니다.
- 사용법: sns.boxplot(x='category', y='value', data=dataframe)
sns.boxplot(x='day', y='total_bill', data=tips)
plt.show()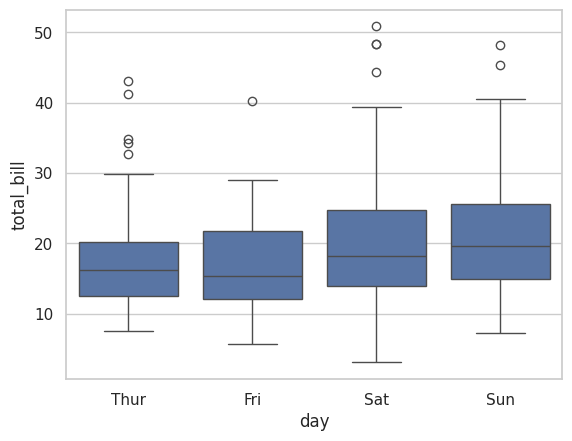
6. Violinplot (바이올린 그림)
- 설명: 데이터의 분포를 시각화하며, 히스토그램과 박스플롯의 특징을 결합한 형태입니다. 데이터의 밀도를 나타냅니다.
- 사용법: sns.violinplot(x='category', y='value', data=dataframe)
sns.violinplot(x='day', y='total_bill', data=tips)
plt.show()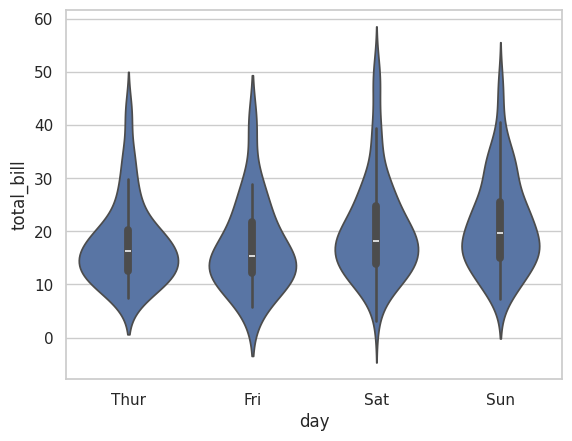
7. Heatmap (히트맵)
- 설명: 값의 크기에 따라 색상으로 데이터를 시각화하는 그래프입니다. 주로 상관관계 행렬을 시각화하는 데 사용됩니다.
- 사용법: sns.heatmap(dataframe, annot=True)
항공 승객 수 데이터를 히트맵으로 시각화하면 월별 승객 수의 변화를 직관적으로 볼 수 있습니다.
다음은 flights 데이터셋을 사용하여 히트맵을 생성하는 예시입니다.
# 피벗 테이블 생성 (행: 월, 열: 연도, 값: 승객 수)
flights_pivot = flights.pivot(index='month', columns='year', values='passengers')
# 히트맵 생성
plt.figure(figsize=(12, 8))
sns.heatmap(flights_pivot, annot=True, fmt="d", cmap="YlGnBu")
plt.title('Heatmap of Flights Data')
plt.show()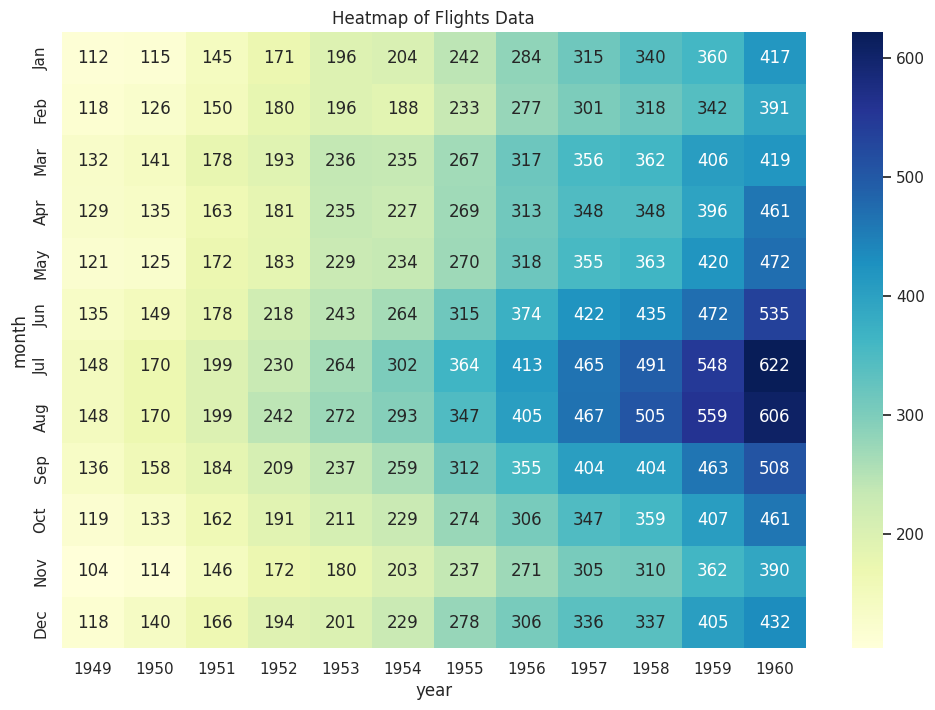
반응형
'코딩 - > 인공지능' 카테고리의 다른 글
| RNN의 모델구조만 보고 RNN을 직접 만들어보자. (0) | 2024.08.21 |
|---|---|
| 파이토치로 기본 사용법, 파이토치 입문 데이터 로드부터 mlp 모델까지 (0) | 2024.08.05 |
| 인공지능 용어 및 요약정리 (0) | 2021.12.13 |

